

- 기술정리 : 밑바닥부터 Kanana LLM 개발하기: Pre-training
- 보조자료 : 밑바닥부터 시작하는 LLM 개발기
- Youtube : 밑바닥부터 Kanana LLM 개발하기: Pre-training
본 글은 Kanana Essence & Nano에 대한 공부&정리글입니다.
Notion에 정리한 글을 Ctrl C+V한 것으로,
요약본을 보고싶다면 GPT에 넣으십시오.
보다 자세한 내용은 1. 기술정리, 2. Youtube + 보조자료 순서로 권장드립니다.
김보섭 mat.mul (pre-training) -18:30
Data strategy
학습데이터 수집 방법론
- 애초에 Staged- pretraining을 염두하고 학습데이터를 수집
- Staged-pretraing이란?
- Stage 후반부에, 고품질의 데이터 왕장 넣어 학습하는 방식
- Staged-pretraing이란?
- kanana 언어모델의 학습데이터는, two-staged-pretraining을 사용
- Stage1 : Data diversity & Quantity(데이터 다양성 & 양)
→ 지금 나처럼 지식이 부족할 때, 논문만 보는게 아닌 이것 저것 다 주워먹는 단계 - Stage2: Data Goal & Quality(데이터 목표 & 품질)
- Stage1 : Data diversity & Quantity(데이터 다양성 & 양)
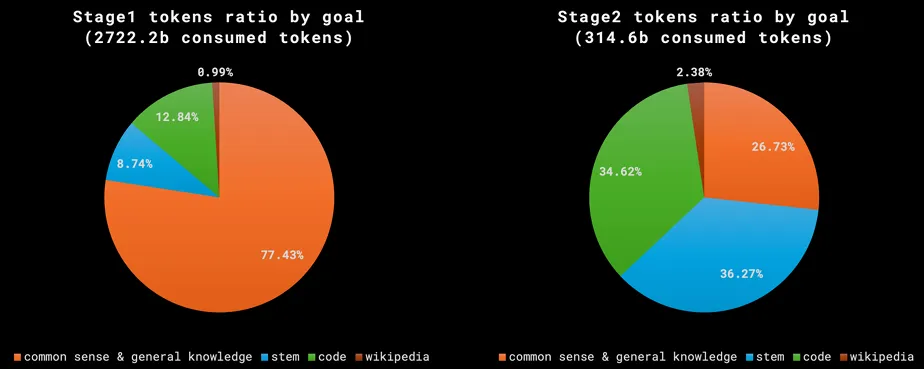
수집된 학습데이터 분포
- 5T(5조) 가량의 학습데이터를 수집
- 학습에 사용해도 상관없는 라이센스에 해당하는 말뭉치를 수집 & Goal 별로 분류
* 라이센스(e.g., apache-2.0, cc-by-4.0 등)
- (Data) Goal에 대한 명확한 분류는, 연구자들 사이에서도 정의되지 않음
→ Kakao만의 정의를 내리고, 수집한 말뭉치를 분류
Goal이 Common sense & General knowledge 인 경우, FineWeb/DCLM-baseline과 유사한 방식으로 진행 
개인정보 익명화/제거가 해당 부분에서 적용
- 학습에 사용해도 상관없는 라이센스에 해당하는 말뭉치를 수집 & Goal 별로 분류
- 이런 과정(Education scorer를 학습시키는 방법)을 기반하면,
Edu scorer 기반으로 데이터를 선별한 경우 성능이 훨 뛰어남을 확인함.

- 영어인 경우(학습 데이터가), stage1/stage2의 학습데이터 구성을 위해,
DataCompLM의 FastText 기반의 quality 모델을 사용함. - Goal이 Code인 경우,
stage1 : starcoderdata, TheStackV2 등 Opensource code 말뭉치
stage2 : stage1에서 골라낸 python(자연어+코드) 관련 데이터 + 추가 SFT 데이터셋.- TheStackV2는, Permissive license만 사용하여, 434B → 133B로 감소됨.
- Goal이 wikipedia인 경우,
stage1 : 한국어, 영어를 포함한 29개 언어에 대한 wikipedia
stage2 : 한국어, 영어 중심의 wikipedia- hugging-face-hub 등 공개된 위키피디아 말뭉치는,
수식처리에서 문제가 있음을 확인.
(e.g.) 코리올리 효과의 경우, 수식 많은데 다 날아가서, 자체적으로 수식처리를 진행함.
- hugging-face-hub 등 공개된 위키피디아 말뭉치는,
- 최종적으로,
Compute budget을 고려하여 5T 가량 토큰 중,3T 가량을 확보,
Stage1 (2.7T), Stage2 (0.3T)을 구성함.- 학습데이터의 Goal별 distribution을 결정하기 위해서, ablation을 많이 수행함.
Training strategy
- 본 파트에서는,
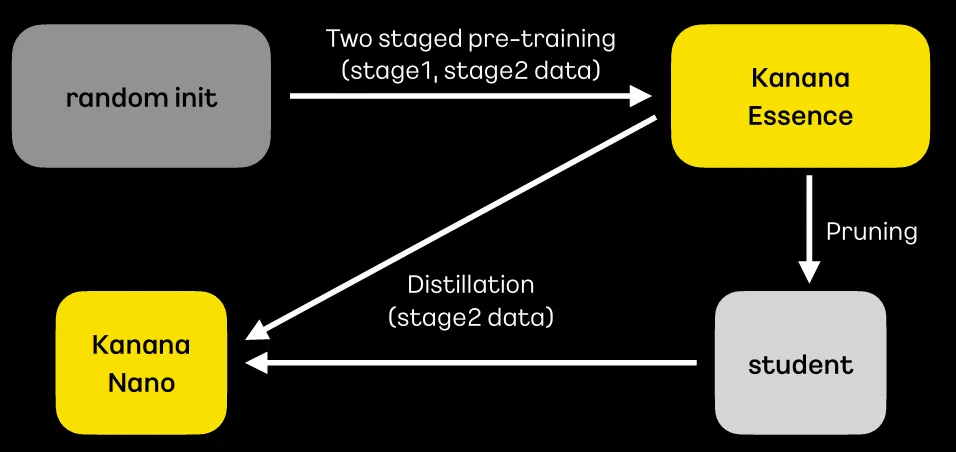
채택한 모델/kanana essence Nano를 확보하기 위해 구사한 전략/stage1,2에서 Goal별 distribution을 결정하기 위한 ablation을 통해 결정한 내용 중점으로 소개함. - Kanana Essence를 먼저 개발, pruning & distillation 기법 적용으로 Kanana Nano를 학습하는 전략 채택
- Kanana Essence
- llama와 유사한 구조를 채택,
context length로 8k를 가지도록 학습함. - 학습 하이퍼 파라미터는,
DeepSeekLLM과 유사한 Multi-step learning rate scheduler를 사용함.
- llama와 유사한 구조를 채택,

- Stage1 학습의 Goal별 distribution 탐색을 위해
250B 가량의 Token budget으로 ablation을 진행. - 한국에 관한 culture-knowledge 학습이 중요하기에,
한국어 벤치마크인 kmmlu, haerae의 점수를 고려하면서,
영어 벤치마크인 mmlu의 점수의 평균을 최대화하는 과정을 진행함.- haerae를 포함한 이유:
해당 연구는 llama2와 같이 오픈소스 모델의 경우, 한국어 말뭉치로 학습된 opensource 모델인
Polyglot-Ko 대비 훨씬 낮은 성능을 보임.- 한국에 관한 culture-knowledge를 kmmlu보다 더 요구하는 벤치마크로 판단하게 됨.
- haerae를 포함한 이유:
- Stage1의 ablation은 다음과 같이 진행함.

- 각각의 ablation에서 250B Token을 학습함.
- ablation0 : 2.7T을 학습할 예정이었으나, 250B만으로도 경향을 알 수 있었음.

- ablation1&3 : baseline 대비 모든 벤치마크에서 성능이 뛰어남.
- ablation3 : ablation1과 비교할 때, mmlu는 낮으나, haerae 벤치마크에서 성능이 뛰어남.
- ablation 결과를 참고하여, ablation1&3을 모두 채택함.
- 추가로, Goal이 Common sense & General knowledge인 영어 말뭉치에 대하여,
Quality scorer 기준으로, 저품질을 제외하는 방식으로 학습데이터를 구성한 결과,
성능의 유의미한 차이를 확인함. 이 설정값을 stage1에 사용함.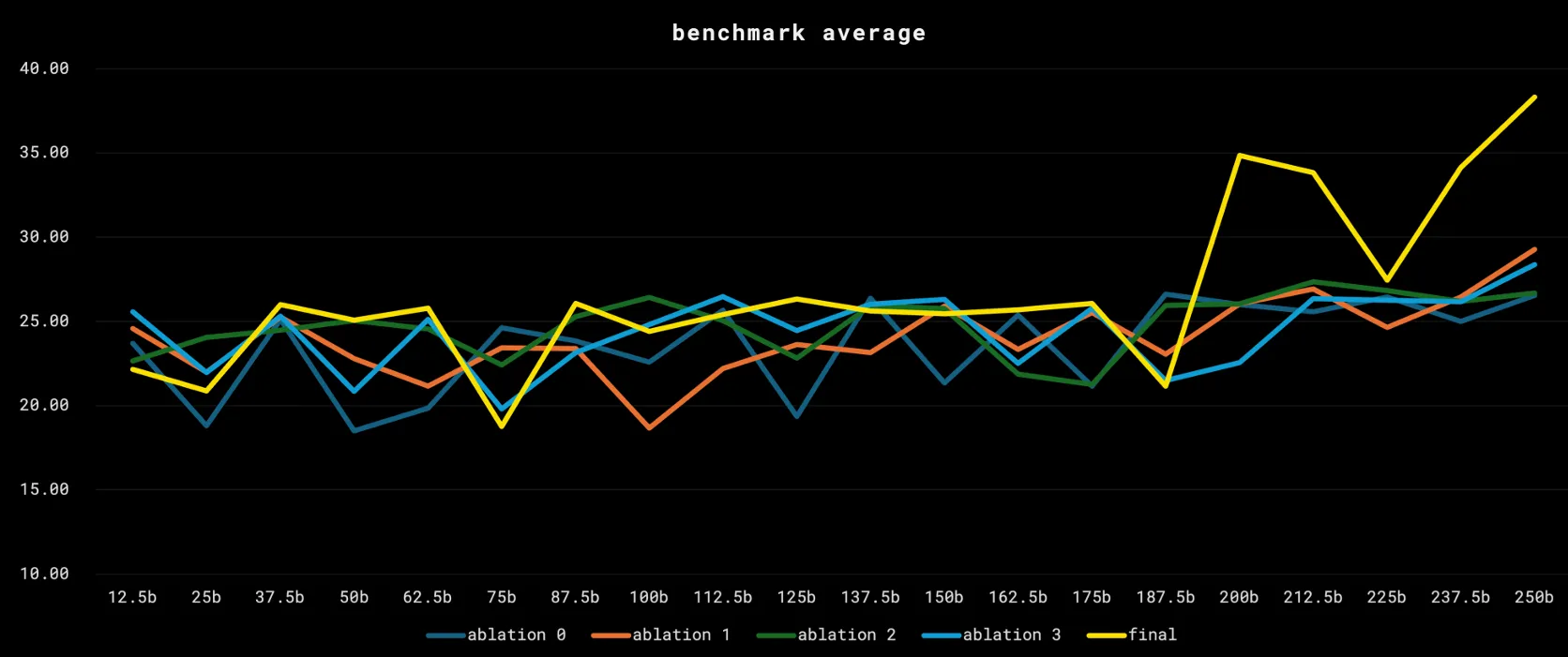
- 추가로, Goal이 Common sense & General knowledge인 영어 말뭉치에 대하여,
- 선정된 학습방식 기반으로, two-stage pretraing의 stage1인 2.7T 토큰을 학습한 뒤, 6개의 벤치마크 성능을 확인함.

- 비슷한 크기의 llama-3.1-8b와 비교하였을 때, kmmlu, haerae에서 보다 뛰어난 성능을 보임.
- 수학/code 관련 벤치마크인 gsm8k, humaneval, mbbp에선 낮은 성능을 보임.
- stage1 결과값을 개선하기 위해, stage2의 학습데이터 구성을 위한 17가지 ablation을 수행함.
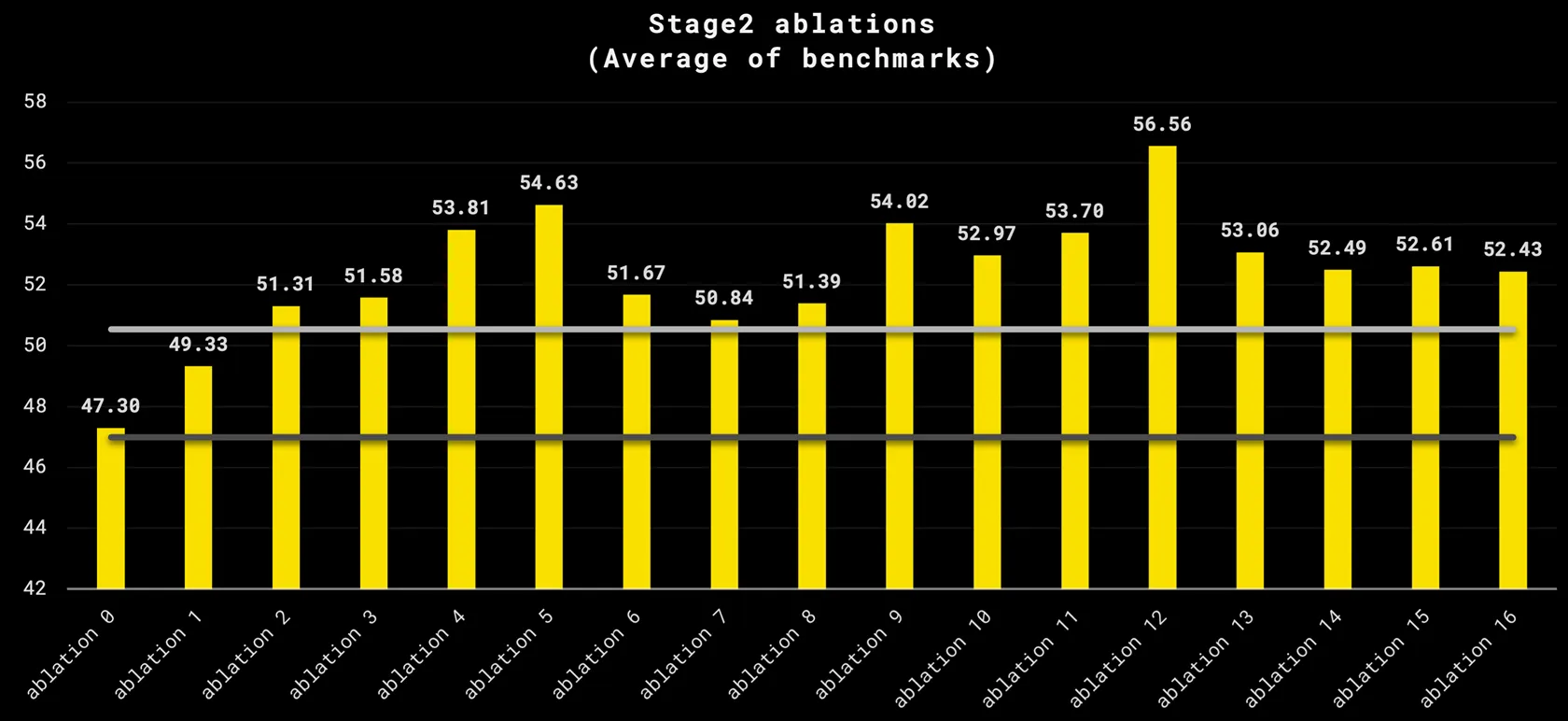
- 6개 벤치마크 성능 평균이, llama-3.1-8b보다 높은 경우를 찾고자 함.
- 결과적으로, ablation12가 선정됨. (얼마나 많이 수행한거야..)
- ablation을 통해 KAKAO가 배운점.
- Staged pretraining에서, Goal별 학습데이터의 distribution을 조정하는 과정이 중요함을 배움.
이러한 과정은, 타 연구의 staged pretraining 활용 결과와 유사함을 나타냄. - Stage2에서 high-quality data를 사용하기에, 적당히 큰 learning late 사용이 필요함을 배움.
- 어느정도의 code/math 관련 instruction data를 추가하는 과정이,
특히 math 관련 벤치마크 성능 증대에 도움이 됨을 배움.
- Staged pretraining에서, Goal별 학습데이터의 distribution을 조정하는 과정이 중요함을 배움.
- ablation 결과로 확인해보자

- baseline : stage1의 Goal별 distribution을 그대로 학습하는 경우, 성능 향상 거의 없음.
- ablation1 : ablation0에서 데이터만 고품질로 교체한 경우, 성능이 아주 조금 증가함.
- ablation1/2/3 : Goal별 distribution을 조정한 경우, 벤치마크 성능을 크게 끌어올릴 수 있었음.
- ablation11 : learning rate를 키우니, 고품질 데이터를 사용하는 경우, learning rate를 잘 사용하는 것이 중요함을 배움.
- ablation12 : SFT 데이터셋을 어느정도 사용하는 것이, Pretraining 관점에서 좋다는 것을 배움.
- ablation12에서, stage3를 진행해보았음.
- Pretraining에서 자주 사용되는 기술인 annealing과 check-point avaraging을 통해, 벤치마크 성능을 끌어올림.
- 이 과정에서, code관련 벤치마크인 mbpp와 humaneval 성능을 끌어올리게 됨.
- 결과, llama-3.1-8b 대비 20%미만의 학습 데이터로, 더 좋은 성능을 pre-training 단계에서 달성함.
- kmmlu와 haerae에서 타 모델 대비 좋은 성능임을 확인함.

- Kanana Nano의 경우,
llama와 유사한 구조 채택, pruning & distilation 기법 적용에 앞서,
학습 레시피 검증을 위해, kanana essence 학습에 사용한 two-stage pretraining 레시피를 그대로 적용하여,from scratch로 학습을 진행
- Kanana Essence로부터 stage2에 활용한 데이터(0.3T)를 활용하여, pruning & distillation을 적용한 결과, 1/10의 데이터만 사용하고도 훨씬 더 좋은 모델을 학습할 수 있음을 확인함(벤치마크에서 from scratch보다 성능이 좋음을 확인).
Further work
- Kanana Essence & Nano 개발에서, 성능 향상과 Kakao에서 추구하는 방향성에 대한 설명.
- Kanana Essence
- gemma-2-9b, qwen2-7b 대비하여, 공통적으로 stem과 science관련 영역 성능이 떨어짐

- Permisive lisence로만 학습데이터 말뭉치를 구성하여, 해당 영역 학습이 부족하다고 판단됨.
- 이외 분야(코드, stem, applied science 등)도, 학습데이터 부족으로 판단됨.
- 현재, 학습 데이터 부족 문제를 해결하여 Kanana flag 모델 학습 진행중임.
- gemma-2-9b, qwen2-7b 대비하여, 공통적으로 stem과 science관련 영역 성능이 떨어짐
온경운 cloud.off (post-training)
Intro: Post-training이란?

- Pre-training = 똑똑하게
- Post-training = 말 잘 듣게
- ”원하는 것을 정확히 수행할 수 있는가?”
Preliminary: 보통 어떻게 하는가?

- 당부드리고 싶은 말.
- Pre-training과 Post-training의 비용 차이는 어마어마하다.
- Pre-training은 모델 라인업 등, 모델 확보가 중요한 이슈이고, Post-training은 말을 잘듣게 하는 레시피(알고리즘&데이터)의 확보가 중요함.
- Post-training 2단계로 나눠 설명할 수 있다.

- Supervised Fine-Tuning (SFT)
: 사용자의 입력 Prompt(instruction)에 맞는 response(answer)를 직접 생성하도록 학습함. - Preference based Learning
: 사용자의 입력 Prompt(instruction)에 상응하는 여러 개의 response(answer)를 통해 더 좋은 response를 강화하고, 안좋은 response를 약화하는 방향으로 학습. - 일반적으로, Supervised Fine-Tuning을 하고, Preference based Learning 순서로 진행함.
- Supervised Fine-Tuning (SFT)
Main result: 우리는 어떻게 했는가?
- Kakao의 recipe(알고리즘&데이터)와 얻은 교훈을 공유하도록 하겠다.
- Kakao Essence model을 Post-training한 결과를 타 모델과 비교한 표/그래프이다.

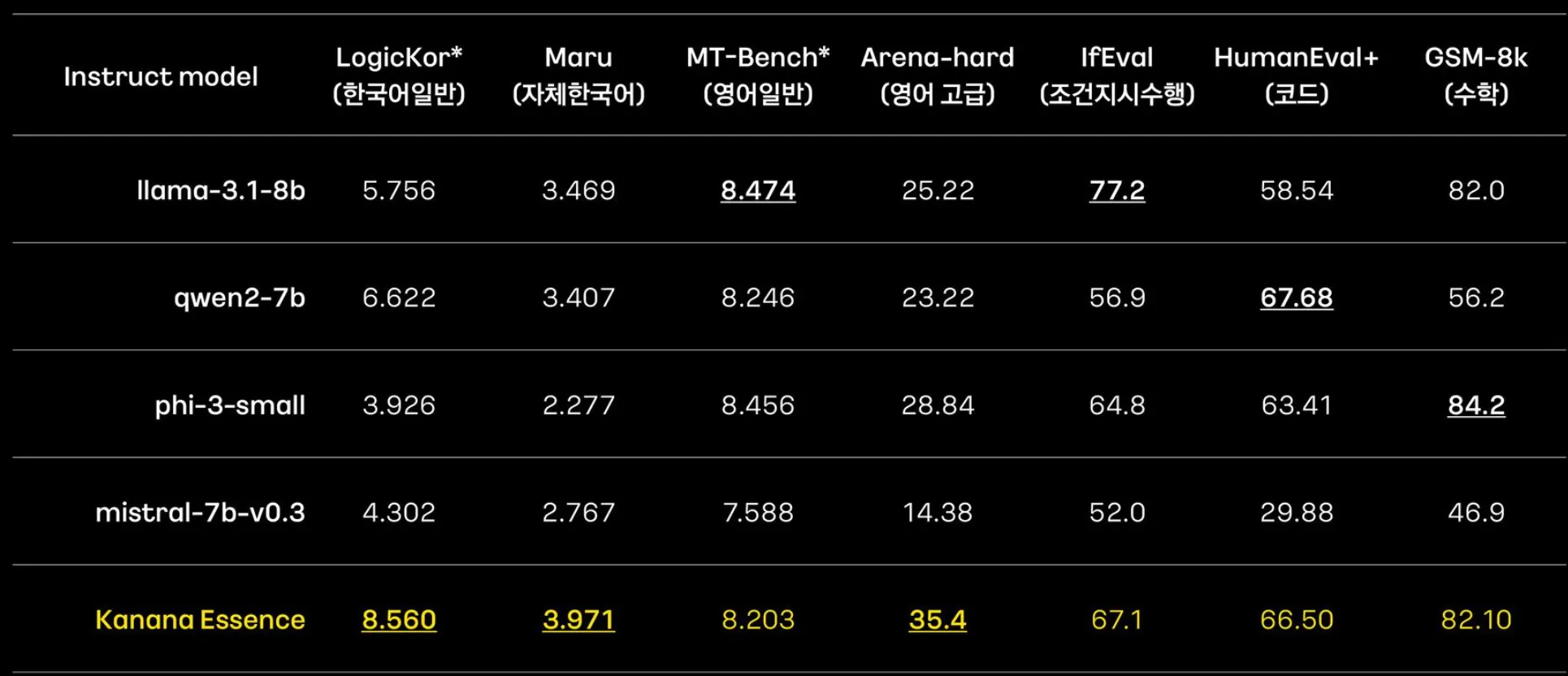
- 타 모델에 비해, 한국어 성능이 확연히 뛰어남.
- Nano model을 비교한 결과, 아래 표처럼 나온다.
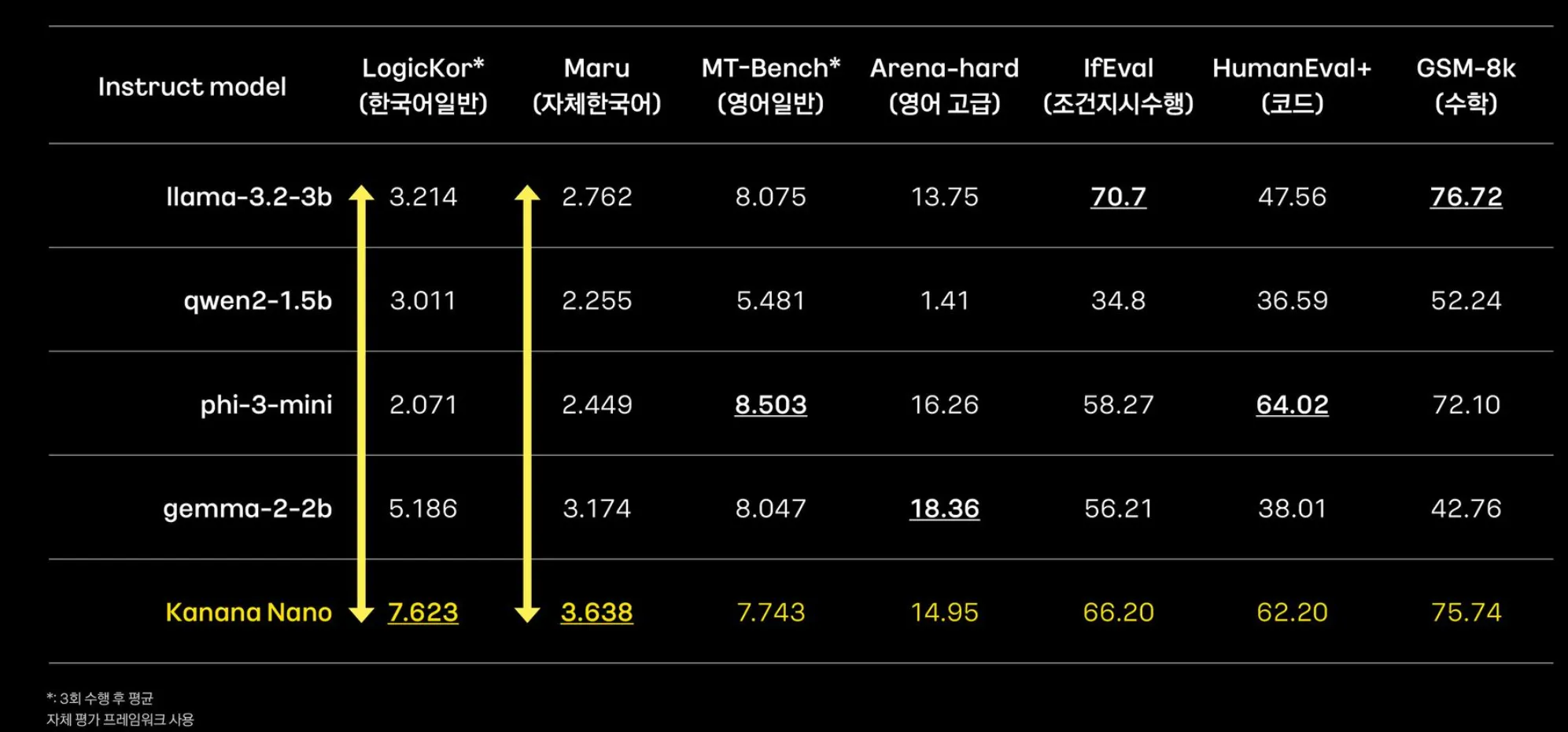
- Nano 모델 결과, 경향성은 비슷하나, 한국어에서 성능 갭이 커지는 현상.
- 모델 사이즈가 작아질수록, multilinguality(다국어에 대한 능력)이 떨어지기 마련임.
- 소형 모델에서, 자체 모델의 필요성이 더 커지지 않나 라고 해석이 가능함.
- Nano 모델 결과, 경향성은 비슷하나, 한국어에서 성능 갭이 커지는 현상.
Key Lessons from Our Recipe (in Supervised Fine-tune)
- 실제 서비스를 사용하는 형태와 유사한 Prompt는 중요함.
- 보다 Natural하게 말하기에, 데이터도 유사하게 만드는 것이 유용함.
- 단순히 계속 질의만 던지는것이 아닌, LLM의 응답에 소통하는 방식으로 사용되고 있음.
- 실험결과, 성능적으로 유의미함을 확인함.
- Prompt말고, response/answer의 quality는 중요함.
- 좋은 quality 답변을 학습한 모델이, 그렇지 않은 모델보다 성능이 높음.
- 좋은 답변은 계속 바뀔 수 있기에, 지속적으로 더 나은 답변을 제공하는 프로세스 구축함.
- 서로 다른 도메인(e.g, 코드, 수학, 조건 형식 등) 데이터셋은 각기 구축이 필요함.
- 각 도메인에 해당하는 데이터셋이 있어야 관련 능력이 발현됨.
- 각 도메인간의 유의미한 성능 간섭은 발생하지 않음.

- 수학 관련 데이터를 넣었다고, code 관련 성능이 떨어지거나 그렇진 않다.
Key Lessons from Our Recipe (in Preference Learning)
4. Preference Data를 “잘” 만드는 것이 중요함.
- 도메인 별로 좋은 preference data를 만들기 위한 전략 수립이 필요함.

- “왼쪽과 오른쪽 중, 어떤 답변이 더 좋냐?”에서, 왼쪽의 답변이 더 자세히 기술되어 좋다고 생각하곤 함.
- 그러나, 왼쪽이 Nagative Response, 오른쪽이 Positive Response임.
- 둘 다 답은 맞았으나, 왼쪽의 풀이과정이 틀렸기 때문임. 수학은 풀이 과정도 중요한 도메인임.
- 이처럼, 도메인마다 답변의 preference를 labeling할 수 있는 각기 파이프라인 구축이 필요함.
5. [onlineness] 학습 시점의 모델의 output을 직접 이용하여, preference를 학습하는 것이 중요함.

- offline과 online의 데이터를 살펴보면, 왼쪽은 답변의 평가를 데이터로 학습하게 됨.
- online은 데이터로는 prompt만 존재하고, prompt에 대하여 LLM이 생성된 답변을 외부 리워드 모델을 이용하여 평가를 받고, 그 정보를 기반으로 학습함.
- 모델의 현재 output을 가지고, 데이터를 만들어 학습한다는 것임.

- reward 모델 기반의 model output을 이용해, iterative하게 학습함.
- 모델의 현재 output을 가지고, 데이터를 만들어 학습한다는 것임.
Further work: 앞으로 어떻게 할건가?
- Recipe 관점에서 Kakao가 추구하는 방향에 대한 설명.
- 두 가지 관점을 주목하고 있음
- 실제 서비스를 사용하는 형태와 유사한 데이터 & Synthetic data generation 접근
- 자연스럽고 다양한 형태의 instruction과, 모델과 소통이 자연스러운 multi-turn 대화
- 사람으로부터 데이터를 생성하지 않고, 모델이 생성할 수 있는 방식을 연구중임.
- MT 벤치 평가세트를 통하여, 모델과 소통이 자연스러운 Multi-turn 데이터가, 좋지 않은 Multi-turn 데이터에 비해 성능 향상이 뛰어남을 확인함.
- 위 실험결과가 아니더라도 Multi-turn에 주목하는 이유는, GPT, Claude와의 차이점은 데이터라고 생각함.
- Code /Math 도메인 한정하여, 초기 실험 결과가 유의미하였고 확장할 계획임.
- Online (Self-play) preference learning
- 기존의 Supervised 와 offline은, 정답을 보면서 학습(SFT) → 다른사람의 오답노트를 보며 학습.

- Online은 모델의 출력을 가지고 학습하는 방식임.

- 모델이 스스로 오답노트를 만들어 학습하는 과정임.
- 최근 연구가 많이 진행되고 있는 분야(2024년 12월 기준).
- Onlineness의 가장 높은 우선순위는, 좋은 reward model을 얻는 것임.
- Rovust reward model 학습
- Process supervision 연구
- General preference with Nash equilibrium 기반 알고리즘 연구
- 2024년 간간히 나오는 연구로, Nash equilibrium이란 개념으로 General perference를 정의한 알고리즘 연구.
- 수학적 진입장벽으로, 활발한 분야는 아님. 그러나, onlineness 측면에서 접근할 부분이 보여 연구중임.
- 기존의 Supervised 와 offline은, 정답을 보면서 학습(SFT) → 다른사람의 오답노트를 보며 학습.
- 실제 서비스를 사용하는 형태와 유사한 데이터 & Synthetic data generation 접근

국내 LLM 공부를 해볼겸, Kakao의 Kanana에 대하여 알아보았다.
어렵다.
'자기개발 > LLM Study' 카테고리의 다른 글
| [LLM] Prompt Engineering이란? (0) | 2025.10.27 |
|---|---|
| [정리] [Upstage] AI 스타트업 개발자는 어떤 툴을 사용할까? Cursor 사용후기 (0) | 2025.05.15 |